In the previous blog, we learned basic terminologies used in reinforcement learning, now we are going to see the basic mathematics and rules behind reinforcement learning i.e MDP.
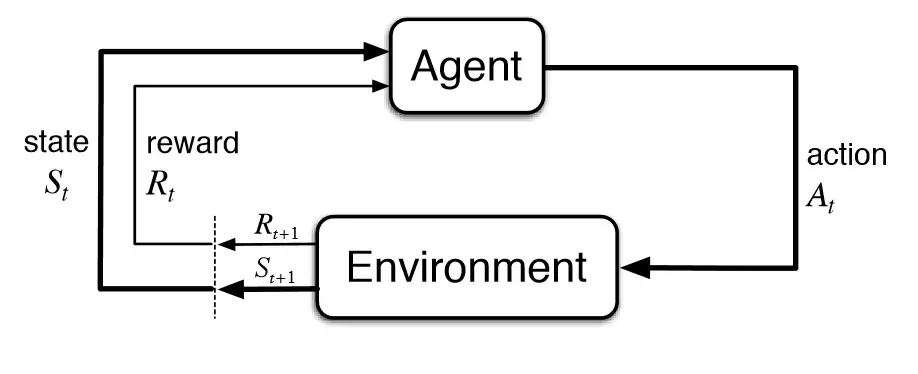
Markov Decision Processes (MDPs) are mathematical frameworks for modeling decision-making problems in which an agent takes actions to maximize a reward signal, that is where MDP is connected with reinforcement learning because in reinforcement learning we also want to maximize the reward. In this blog post, we’ll take a closer look at what MDPs are, how they are constructed, and how they can be solved. But before going toward MDP need to see the fundamentals of MDP i.e Markov Property and Markov Chain, on which we are building MDP.
Markov Property
The Markov property is a fundamental concept in Markov Decision Processes (MDPs). It states that the future is independent of the past given the present. In other words, the future state of a system depends only on the current state and the actions taken, and not on any previous states or actions.
Formally, the Markov property can be expressed as follows:
For any state s and any time step t, the probability distribution over future states, given the history of states and actions up to t, is equal to the probability distribution over states at time t+1, given only the state at time t.
This property makes MDPs well-suited for modeling decision-making problems where the future is uncertain, but the uncertainty can be reduced by taking action and observing the results.
The Markov property is a key requirement for MDPs because it allows us to model the decision-making process in a way that is computationally tractable. By assuming the Markov property, we can simplify the problem of finding an optimal policy by considering only the current state and the immediate rewards and transitions, rather than the entire history of the system. This allows us to use algorithms like value iteration, and policy iteration to solve the MDP efficiently. Now we will take a look at Markov Chain.
Read More »