

Reinforcement learning For Absolute Beginners
This blog is the continuation of the Machine Learning blog series for Absolute beginners. In the previous blog, we give a brief introduction to the three categories of machine learning. Now we will dive deep into one category of Machine learning i.e Reinforcement Learning.
Let’s start with a basic introduction to Reinforcement Learning which basically helps an agent to learn in an interactive environment by trial and error using feedback from its own actions and experiences. The agent takes some action in a particular situation in the environment. And that action may or may not affect the state of the environment. But the environment in return gives a reward that may be positive or may be negative depending on the performed action on the environment.
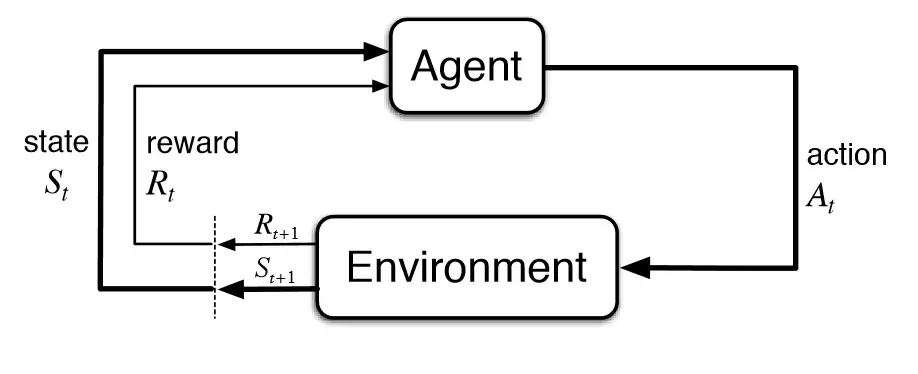
In Reinforcement Learning, the agent learns automatically using feedback without any labeled data, unlike supervised learning. Since there is no labeled data, so the agent is bound to learn by its experience only. The agent interacts with the environment and explores it by itself. The primary goal of an agent in reinforcement learning is to improve performance by getting the maximum positive rewards. Let’s discuss one example.
Example: Suppose there is an AI agent present within a maze environment, and his goal is to find the diamond. The agent interacts with the environment by performing some actions, and based on those actions, the state of the agent gets changed, and it also receives a reward or penalty as feedback.
In the above example, we discuss that an AI agent performs one action and will collect the negative or positive reward. And similarly, the AI agent performs the second action and will get the second negative or positive reward but that is not the case all the time. Sometimes in Reinforcement learning, the reward comes late. Let’s discuss another example.
Example: We will take an example of an AI agent driving a vehicle and it hits another vehicle by accident. AI agent’s vehicle is moving at 100 km/h in a city. And just before hitting another vehicle AI agent applied a brake. So, his last action before an accident is applying a brake. So, If we give a negative reward for the action of applying the brake, then the AI agent learns that applying a brake is not a good action, because after applying the brake, we had an accident. So, the Conclusion will be applying a brake is the cause of the accident, but the actual reason for the accident is overspeeding. So, accelerating the speed is one action but the reward of this action comes later after taking another action. So, the agent should be able to learn that driving fast is not a good habit. So, the actual problem in reinforcement learning is dealing with a reward function. How to design the reward function is the real challenge? we will discuss later, how we resolved that issue. But first, we need to understand the basic terminologies used in reinforcement learning.
Basic Reinforcement Learning Terminologies
Agent:
The agent or the learner that entity performs the particular action in a particular state in the environment according to the policy and gets the rewards.
Collaborative:
When two AI agents both want to increase their utility and due to that it does not affect the utility of the second agent. For example, a Zero-Sum game in which there are two AI agents A and B and there are groups of blocks of 2 different colors e.g Red and Green. So if AI agent A wants to collect blocks of Red and AI agent B wants to collect green blocks, so they both will collect blocks that will not affect the other AI agent’s utility, such kinds of AI agents are called Collaborative agents.
Adversarial:
When two AI agents both want to increase their utility and due to that it affects the utility of the second agent. Like if there are two AI agents A and B and there is one block that they both want to get, and if AI agent A gets that block then it would be a loss for the second AI agent i.e agent B. Such kinds of AI agents are called Adversarial agents.
Environment:
The training situation that the model must optimize is called its environment. It is the surroundings through which the agent moves. The environment considers the action and the current state of the agent as the input and grants a reward for the agent and the next state, and that is the output.
State:
State refers to the current situation returned by the environment. The state contains all the useful information the agent needs to make the right action.
State Space
The State Space is the set of all possible states our agent could take in order to reach the goal.
Action:
The action taken by the agent on the particular state to move to the next state.
Action Space:
The finite set of all possible actions that the agent can take in any state.
Policy:
A policy can be defined as the way how an AI agent behaves in a particular state. It maps the current state of the AI agent to the next state after performing a particular actions taken in the current state . A policy is the core element of the RL as it alone can define the behavior of the agent. In some cases, it may be a simple function or a lookup table, whereas, in other cases, it may involve general computation as a search process. It could be a deterministic or a stochastic policy: let’s discuss stochastic and deterministic policy.
Deterministic:
When an AI agent is in a particular state and performs a particular action and AI agent knows well that after performing this action AI agent will be in that state. Suppose an AI agent performed an action move right, then the AI agent will move one step towards the right so now the state is changed i.e one step towards the right. So in deterministic policy AI agents knows before performing an action in which state the AI agent will land after performing an action.
Stochastic
When an AI agent is in a particular state and performs a particular action and AI agent knows only the probability of landing in a particular next state. Suppose an AI agent performed an action move right, then there will be an 80% possibility AI agent will move one step towards the right so now the state is changed i.e one step towards the right. But there is a 20% possibility that the AI agent will slip and move to one step down. So in Stochastic policy AI agents know only the probability of landing in a particular state after performing a particular action.
Reward:
To help the model move in the right direction, it is rewarded/points are given to it to appraise some action. The reward signal that the agent observes upon taking a particular action and the goal of reinforcement learning is defined by the reward. At each state, the environment sends an immediate signal to the learning agent, and this signal is known as a reward. These rewards are given according to the good and bad actions taken by the agent. The agent’s main objective is to maximize the total number of rewards for good actions. The reward signal can change the policy, such as if an action selected by the agent leads to a low reward, then the policy may change to select other actions in the future.
Value Function:
The value function gives information about how good the situation and action are and how much reward an agent can expect. A reward indicates the immediate signal for each good and bad action, whereas a value function specifies the good state and action for the future. The value function depends on the reward as, without reward, there could be no value. The goal of estimating values is to achieve more rewards.
Model:
The last element of reinforcement learning is the model, which mimics the behavior of the environment. With the help of the model, one can make inferences about how the environment will behave. Such as, if a state and an action are given, then a model can predict the next state and reward. The model is used for planning, which means it provides a way to take a course of action by considering all future situations before actually experiencing those situations. The approach for solving the RL problems with the help of the model is termed the model-based approach. Comparatively, an approach without using a model is called a model-free approach.
Conclusion:
In this blog, we discuss reinforcement learning in depth and comparison with supervised and unsupervised learning, and also some key terminologies will be used in future blogs. In this next blog, we will move to the basic functionality of reinforcement learning.

[…] the previous blog, we learned basic terminologies used in reinforcement learning, now we are going to see the basic […]
LikeLike